

Google no puede rastrear todo lo que hay en la web; reparte recursos entre sitios y decide qué URLs visita y con qué frecuencia. A ese reparto lo llamamos crawl budget o presupuesto de rastreo.
Si tu sitio es pequeño o Google suele pasar el mismo día que publicas, probablemente no tengas que preocuparte; pero en sitios grandes la gestión del presupuesto marca la diferencia entre que lo importante se rastree a tiempo… o se quede fuera durante días.
Google orienta esta guía principalmente a sitios de 1M+ URLs o a sitios de 10k+ URLs que cambian a diario. No son umbrales estrictos, pero sirven para saber cuándo conviene auditar el rastreo con lupa.
¿Qué es el crawl budget para Google?
Crawl budget es el número de URLs que Googlebot puede y quiere rastrear en tu sitio en un momento dado. Surge del equilibrio entre límite de rastreo (crawl rate limit, lo que Googlebot puede hacer sin sobrecargar tu servidor) y demanda de rastreo (crawl demand, lo que sus sistemas consideran valioso o fresco).
Entendamos mejor estos dos componentes:
- Límite de rastreo: controla la concurrencia y el intervalo entre solicitudes de Googlebot hacia tu host. Si tu servidor responde rápido y estable, el límite sube; si responde lento o devuelve muchos 5XX/429, baja.
- Demanda de rastreo: determina cuánto quiere rastrear Google según señales como popularidad y antigüedad (para evitar que las URLs queden obsoletas); también puede subir temporalmente tras eventos como cambios masivos de URLs.
¿Qué cuenta como gasto de rastreo?
Cada solicitud que Google hace a tu host consume recursos: HTML de páginas y también archivos auxiliares (imágenes, CSS, JS, fuentes), que ves desglosados por tipo en el informe Estadísticas de rastreo de Search Console. Por eso la velocidad de respuesta, la estabilidad y el volumen de recursos que sirves influye en el ritmo sostenible de rastreo.
Reducir errores, servir respuestas consistentes y no multiplicar variantes innecesarias ayuda a que el presupuesto se invierta donde importa.
Una etiqueta noindex evita la indexación, pero no impide el rastreo; de hecho, Google debe poder acceder a la URL para ver ese noindex. Si el objetivo es que no se rastree, la vía es bloquear en robots.txt aquellas rutas que no deben solicitarse (por ejemplo, parámetros sin valor SEO). De lo contrario, seguirás viendo hits de Googlebot en esas URLs aunque no se indexen.
Cuando preocuparte por el presupuesto de rastreo de tu web
Si tu web es pequeña o mediana y las páginas nuevas se rastrean en unos días, no hay motivo para obsesionarse con el crawl budget. Google indica que, para la gran mayoría de sitios, lo normal es tres días entre publicación y rastreo, y que no suele ser un problema salvo en proyectos grandes o que generan muchas URLs.
Si tienes menos de 10.000 URLs, normalmente se rastrea con eficiencia.
Empieza a preocuparte cuando detectes señales de cuello de botella: un acumulado de Descubierta: actualmente no indexada en el informe de indexación (Google conoce la URL pero aún no la ha rastreado), avisos de hostload exceeded o picos en Disponibilidad del host en Estadísticas de rastreo, tiempos de respuesta altos o errores 5xx/429 sostenidos, y, al revisar logs, mucho rastreo gastado en parámetros, facetos o soft 404 mientras secciones importantes quedan atrás.
Estas señales indican que Google está limitando el ritmo por capacidad o que está invirtiendo el rastreo en URLs de bajo valor, y es el momento de auditar.
Factores que consumen crawl budget
El presupuesto de rastreo se va por dos vías: muchas URLs de poco valor (Google invierte tiempo donde no aporta) y limitaciones del host (latencia alta y errores que bajan el ritmo de Googlebot). Identificar estos focos y contenerlos evita que el crawl budget se diluya lejos de tus páginas importantes.
- Navegación facetada, parámetros y session IDs: generan combinaciones casi infinitas y duplicadas que absorben rastreo sin aportar contenido nuevo.
- Contenido duplicado o canónicos mal aplicados: duplicados internos y señales contradictorias llevan a Google a rastrear versiones redundantes. Aquí te dejamos una guía para evitar el contenido duplicado en tu web.
- Soft 404: páginas inexistentes que responden 200. Devuelve 404/410 reales para cortar rastreos inútiles.
- Espacios infinitos: calendarios, paginación sin fin o proxys que destapan URLs interminables; bloquéalos en robots.txt.
- Páginas de baja calidad, hackeadas o spam: Google las clasifica como low-value-add y consumen presupuesto; limpia o elimina.
- Páginas que ejecutan acciones (carrito, checkout, login) o scroll infinito: poco valor para búsqueda; considera excluir su rastreo.
- Recursos de renderizado pesado (JS/CSS) en tu dominio: el rastreo de recursos para renderizar consume presupuesto del hostname que los sirve; minimiza peso y peticiones.
- Confiar en noindex para ahorra crawl budget: Google necesita cargar la URL para ver el
noindex; si buscas evitar la solicitud, usa robots.txt en variantes sin valor.
Cómo diagnosticar: auditoría de crawl budget paso a paso
Ahora que ya tienes los conocimientos básicos sobre el crawl budget, te vamos a explicar cómo pasar de sospechas a un diagnóstico operativo funcional. El objetivo es detectar si Google está limitado por tu capacidad del host o si está gastando rastreos en URLs de poco valor.
Trabaja con un periodo de 30-90 días y centra el análisis en las secciones que realmente te importan.
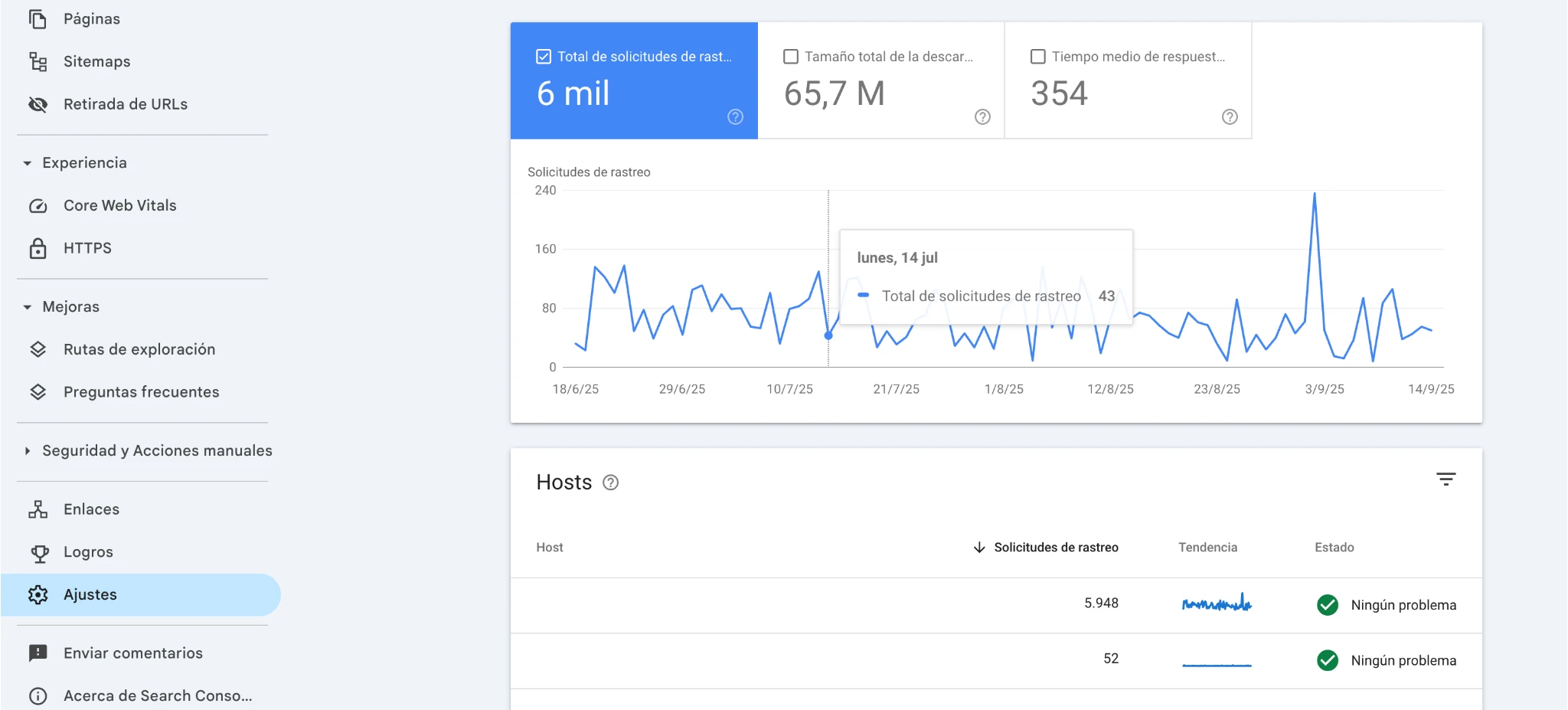
1. Mide el ritmo real en Search Console (Estadísticas de rastreo)
Abre Ajustes –> Estadísticas de rastreo y revisa: solicitudes totales, tiempo medio de respuesta, picos de 5xx/429 y avisos de disponibilidad del host. Si el servidor responde lento o con errores, Google reduce el ritmo; cuando se estabiliza, lo aumenta. Este informe es tu panel para ver carga, códigos HTTP y tipos de archivo solicitados.
2. Contrasta con la cobertura de indexación
Comprueba estados como Descubierta: actualmente no indexada (Google conoce la URL pero aún no la ha solicitado) frente a Rastreada: actualmente no indexada (problema más ligado a calidad/duplicidad). Usa la Inspección de URL (barra de búsqueda que aparece arriba) para ver el detalle.
3. Analiza logs y verifica que sea Googlebot
Extrae peticiones del bot y verifícalas por DNS inversa + directa (no te fíes solo del user-agent). Calcula distribución por códigos HTTO, ratio HTML vs. recursos, rutas con más hits «inusuales» (parámetros, facetas, soft 404) y el tiempo hasta re-rastreo de tus páginas clave. Esto te dirá dónde se consume el presupuesto de verdad.
4. Usa los sitemap como control de inventario
Valida que el sitemap solo incluya URLs prioritarias y que el <lastmod> sea veraz y consistente (Google lo puede usar para programar rastreos si confía en él). Cruza sitemap ↔ logs: si hay URLs del sitemap sin hits recientes de Googlebot, hay atasco que debes resolver. Segmenta por secciones para priorizar.
5. Revisa directivas y caching (robots.txt, noindex. ETag/Last-Modified)
Define en robots.txt qué espacios no deben rastrearse (no lo uses para sacar páginas del índice) y usa noindex cuando busques desindexar; son objetivos distintos. Reduce carga habilitando ETag/Last-Modified: cuando Google ve que hay cambios, puede responder 304 y ahorras solicitudes costosas.
Con estos cinco pasos obtienes una foto clara: si hay cuello de capacidad, si el rastreo se malgasta en rutas sin valor y dónde actuar primero para recuperar crawl budget.
Preguntas frecuentes sobre el crawl budget
Crawl rate limit es el tope de solicitudes que Googlebot puede hacer sin sobrecargar tu servidor (depende de latencia y errores). Crawl demand es cuánto «quiere» rastrear tu sitio según popularidad, frescura y cambios. El crawl budget resulta del equilibrio de ambos.
En sitios pequeños/medianos no suele ser un problema si las páginas se rastrean en pocos días. En sitios grandes o con muchas combinaciones de URLs sí impacta: hay que controlar el inventario de URLs, revisar logs y segmentar sitemaps.
Más recursos para renderizar elevan la carga del host y ralentizan el ritmo útil de rastreo. Además, las rutas generadas solo en cliente pueden tardar en descubrirse.
No aumenta el presupuesto, pero ayuda a dirigir el rastreo hacia lo importante y a detectar atascos al cruzarlo con logs e informes de cobertura.







