

Hace apenas un año, el core update de marzo de 2024 integró definitivamente el Helpful Content System en el algoritmo principal de Google con el objetivo declarado de reducir en un 45% la visibilidad de páginas pocos útiles o recicladas en las SERP. Esta actualización (sumada a nuevas políticas antispam) puso en el punto de mira un viejo conocido del SEO: el contenido duplicado.
La popularización de la IA generativa y la rapidez con la que muchos sitios reutilizan descripciones de productos, notas de prensa o feeds externos han multiplicado las versiones casi idénticas de un mismo texto en la web.
El resultado es competencia interna entre tus propias URLs, señales confusas para los motores de búsqueda y, en el peor de los casos, pérdida de autoridad y de tráfico orgánico. Aunque Google no penalice automáticamente el contenido duplicado, sí puede filtrar las páginas afectadas, mermando su capacidad para posicionar.
En esta guía aprenderás, paso a paso, qué es y qué no es contenido duplicado, por qué puede sabotear tu estrategia SEO y cómo detectarlo con las mejores herramientas. Tanto si gestionas un e-commerce con miles de fichas como si administrar un blog corporativo, aquí encontrarás un plan de acción claro ¡Sigue leyendo!
Qué es el contenido duplicado y qué no lo es
Google define el contenido duplicado como bloques sustanciales de texto, dentro o entre dominios, que coinciden completamente o son muy parecidos. En la práctica, no hace falta que el texto sea idéntico palabra por palabra: basta con que la intención, la estructura y la mayor parte de las frases sean las mismas para que los algoritmos lo detecten.
Por ejemplo:
- Dos URLs con la misma ficha de producto, una en HTTP y otra en HTTPS.
- Páginas impresas (
"/print/") o con parámetros UTM que replican el contenido principal. - Versiones sindicadas de un artículo que aparece en varios medios sin cambios sustanciales.
Lo contrario, párrafos parafraseados, resúmenes o traducciones con valor añadido, no suele considerarse duplicado siempre que aporten contexto nuevo al usuario.
En el día a día del SEO distinguimos dos escenarios:
El contenido duplicado interno aparece cuando varias URLs de tu propio dominio muestran bloques sustancialmente idénticos. El efecto inmediato es que esas páginas compiten entre sí por las mismas consultas, diluyen los enlaces entrantes y consumen más presupuesto de rastreo de Google.
El contenido duplicado externo, en cambio, ocurre cuando ese mismo texto se publica también en otros dominios, ya sea porque lo has publicado tu, te lo han copiado o usas notas de prensa sin modificar. Aquí el riesgo es que un sitio ajeno consiga posicionar antes que tu versión original y se lleve el tráfico y la autoridad que te correspondían.
| Tipo de duplicado | Dónde ocurre | Por qué importa |
|---|---|---|
| Interno | Dentro de tu propio dominio | Canibaliza palabras clave, diluye enlaces y hace que Google gaste crawl budget. |
| Externo | En sitios de terceros | Otro dominio puede posicionar antes que tu, robándote tráfico y autoridad. |
En 2025, los e-commerce y los sites con catálogos amplios siguen siendo los grandes generadores de duplicado interno: fichas casi idénticas, variantes de colores y paginaciones infinitas. Por otro lado, los medios y blogs sufren más el duplicado externo (scrapers, notas de prensa copiadas, IA generativa sin edición humana).
¿Existe una penalización por contenido duplicado?
La idea de una duplicate content penalty es un mito que Google desmontó ya en 2008 y sigue recordando en sus Office Hours. Lo que sí ocurre es:
- Filtrado o consolidación. Google elige una versión canónica de entre todas las duplicadas y oculta las demás en los resultados.
- Pérdida de señales. Los enlaces y las métricas de usuario se reparten entre varias URLs, debilitando cada una de ellas.
- Acción manual (excepcional). Solo si el duplicado forma parte de una táctica manipuladora (por ejemplo, contenido escalado o site reputation abuse) puede llegar una sanción de spam.
Por qué el contenido duplicado afecta al SEO y a tu negocio
Cuando varias URLs muestran el mismo texto, Google elige una sola versión canónica para el índice y filtra las demás. Esa selección reduce la visibilidad de las páginas duplicadas y, de paso, consume crawl budget: cada copia se lleva un rastreo que podría haberse dedicado a nuevas publicaciones o a secciones importantes de tu sitio.
Para el usuario, encontrarse con contenido repetidos dentro o fuera de tu dominio provoca frustración y rebotes, señales que el buscador interpreta como mala experiencia.
Además, como ya hemos comentado, el duplicado dispersa la autoridad. Los enlaces externos y clics internos se reparten entre distintas versiones de un mismo recurso; el link juice y las métricas de comportamiento ya no se concentran en una sola URL que pueda competir con fuerza en los resultados de búsqueda.
A largo plazo, la repetición afecta también a tu marca. Un sitio que parece copiar y pegar inspira poca confianza, dificulta la construcción de EEAT (experiencia, pericia, autoridad y confiabilidad) y se vuelve menos atractivo para recibir backlinks de calidad.
La mezcla de menor visibilidad, pérdida de autoridad y percepción negativa puede traducirse en menos tráfico, menos leads y, en última instancia, menos ingresos.
Principales causas de contenido duplicado
Gran parte del contenido duplicado surge por la combinación de fallos técnicos, decisiones editoriales poco cuidadas y prácticas de terceros sobre las que a veces no tenemos control.
Identificar la fuente exacta es muy importante para aplicar la solución correcta, de lo contrario, se corre el riesgo de tapar el síntoma sin eliminar el problema real.
- Variantes de URL: versiones HTTP / HTTPS, con y sin www, mayúsculas vs. minúsculas, barras finales (/), uso de
index.htmlodefault.asp, etc. - Parámetros, filtros y faceted navigation: cadenas como
?color=rojo&size=M, IDs de sesión, trackers UTM y resultados de buscador interno que generan infinitas combinaciones de la misma página. - Paginación e infinite scroll mal implementados: series /
page/2/, /page/3/que replican grandes fragmentos del contenido principal sin canonical orel="prev/next"apropiados. - Versiones alternativas (printer-friendly, AMP, PDF, páginas móviles antiguas, HTTP/ 2 push, etc.) publicadas fuera del dominio canónico o sin rel-canonical cruzado.
- Fichas de producto clonadas: descripciones proporcionadas por el fabricante, variaciones de color/talla en URLs propias y landings filtradas (
"/camiseta?color=blanco"). - Scrapers y content farming externo: sitios que copian por completo tus textos y los indexan antes de que Google vea tu versión.
- Plantillas CMS demasiado rígidas: bloques idénticos (avisos legales, menús, sidebars extensos) que ocupan la mayor parte del HTML y eclipsan el contenido único.
- Etiquetas, categorías y archivos duplicados: taxonomías creadas sin estrategia que muestran listados de posts con el mismo fragmento de introducción.
- Traducciones automáticas o IA sin edición humana: versiones en otros idiomas o spins generados por inteligencia artificial que apenas cambian sin aportar contexto ni profundidad.
- Migraciones o dominios espejo mal gesitonados: staging sites indexados, dominos antiguos activos o subdominios de pruebas accesibles al crawler.
Revisar regularmente estos puntos, sobre todo en sitios grandes o en crecimiento rápido, te ayudará a prevenir la mayoría de los problemas de contenido duplicado antes de que afecten a tu posicionamiento orgánico.
Cómo detectar contenido duplicado paso a paso
Antes de meternos en herramientas y comandos conviene entender qué vamos a buscar y por qué. El objetivo es localizar cualquier bloque de texto o URL que, a ojos de Google, resulte tan parecido a otro que no aporte información nueva.
Una vez sepamos dónde se repite el contenido, podremos decidir si queremos consolidar, canonizar, reescribir o, simplemente, dejarlo tal cual.
Con esa idea clara, exploremos los cuatro caminos más eficaces para detectar duplicados:
Métodos rápidos: Google como detector de duplicados
El buscador es tu herramienta más accesible. Abre una pestaña de incógnito y escribe:
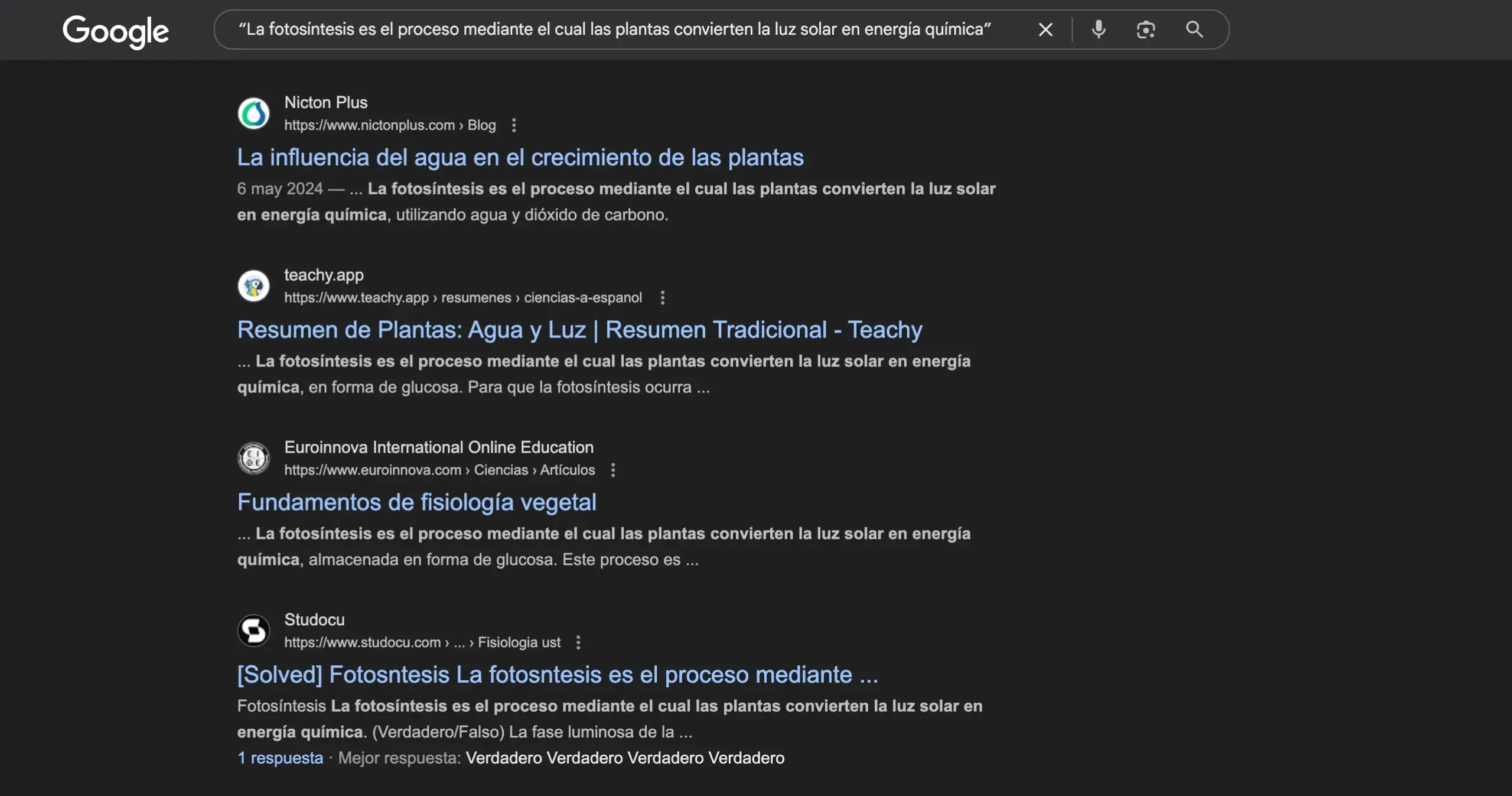
1. Comando site: más una frase exacta de tu página.
Por ejemplo:
site:tutienda.com "sudadera con capucha orgánica unisex"
Si Google devuelve más de una URL con la misma frase, tienes un duplicado interno.
2. La misma frase, pero sin site:.
Así descubres si otra web ha copiado tu texto. Si la URL que aparece primero no es la tuya, toca tomar medidas.
3. Operadores inurl: o intitle: para variantes comunes.
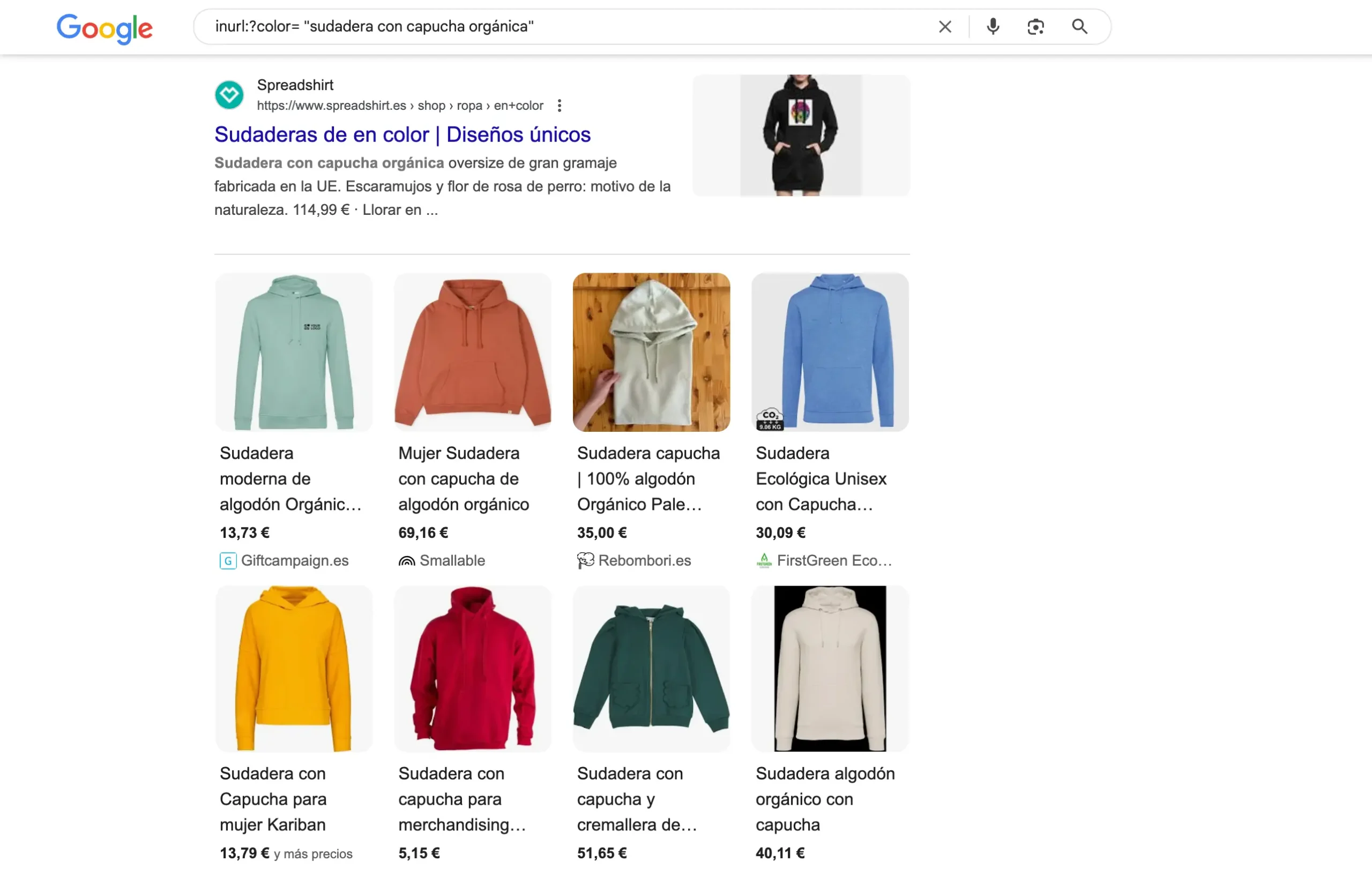
inurl:?color= "sudadera con capucha orgánica"
Con un par de pruebas verás enseguida si los filtros o parámetros están creando clones de producto.
Estos comandos no requieren software ni registro y ofrecen una vista instantánea de lo que ya está indexado. Su límite es que los resultados deben inspeccionarse a mano, por eso enseguida pasamos con auditorías más completas.
Auditoría con Search Console y Screaming Frog
Google Search Console (gratuita) muestra la versión del problema vista por Google.
- En el menú lateral ve a Indexación –> Páginas.
- Fíjate en el estado Contenidos duplicados sin etiqueta canónica seleccionada por el usuario.
- Descarga el informe CSV y observarás que URLs considera repetidas.
- Revisa cada caso y decide: 301,
rel=canonical, noindex o reescritura.
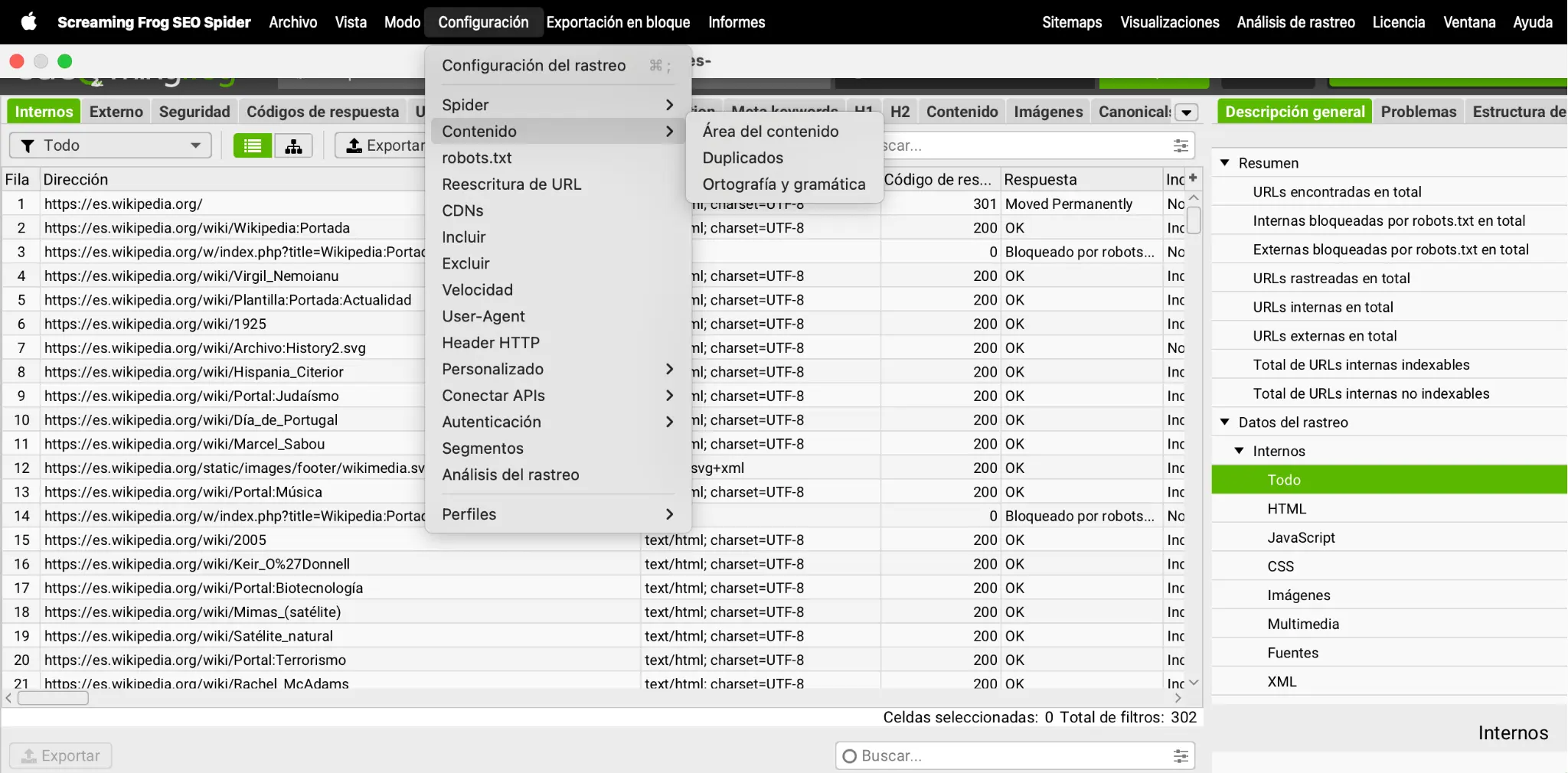
Screaming Frog (versión gratuita hasta 500 URLs o de pago para sitios grandes) rastrea lo que existe en tu servidor, esté o no indexado.
- Lanza un crawl con la opción Configuration –> Content –> Duplicates –> Near Duplicates activada.
- Al terminar, abre la pestaña Content y verás dos columnas: Exact duplicates y Near duplicates, con el porcentaje de similitud y un identificador de clúster.
- Exporta los resultados y ordénalos por clúster; así verás de un vistazo qué URLs son idénticas y cuáles se parecen mucho.
- Decide acción: consolidar, combinar, reescribir o añadir canónica.
Utilizar las dos fuentes es muy potente: Search Console revela cómo interpreta Google tu sitio; Screaming Frog destapa páginas que tal vez el algoritmo aún no rastreo.
Herramientas profesionales: cuándo merece la pena
- Ahrefs Site Audit. Ideal para proyectos medianos o grandes que ya usan Ahrefs para backlinks. Su informe Content Quality agrupa duplicados y enlaza con datos de enlaces y tráfico.
- Semrush Site Audit. Muy visual: marca en rojo las páginas duplicadas e indica si la canónica está ausente o mal definida. Integración directa con métricas de visibilidad.
- DinoRANK. Alternativa económica en español; sus semáforos simplifican la decisión de reescribir o canonizar.
- Copyscape (o PlagScan). Foco exclusivo en plagio externo: avisa cuando otro dominio publica tu texto antes que tú.
La inversión se justifica cuando el sitio supera varios miles de páginas o cuando necesitas alertas automáticas de plagio externo. Para webs pequeñas basta con la pareja Search Console + Screaming Frog y alguna búsqueda manual en Google.
Checklist práctico: ¿Tengo contenido duplicado en mi web?
Lee cada punto y responde con sinceridad sí o no. Cada no señala la próxima tarea que debes abordar.
Checklist: ¿Tengo contenido duplicado en mi web?
Completar el checklist (marcarlo todo en la columna Sí) significa que has controlado las fuentes más habituales de contenido duplicado. Si aún no lo has conseguido, no te preocupes: en el siguiente apartado te enseñamos a solucionar y prevenir cada caso.
Cómo solucionar y prevenir el contenido duplicado
A estas alturas ya sabes localizar las URLs que compiten entre sí y por qué resulta tan costoso dejarlas sin control. El siguiente paso es poner orden: consolidar versiones, indicar a Google cuál debe indexar, bloquear lo prescindible y diseñar tu sitio para que cada intención de búsqueda viva en una sola dirección.
Las cuatro palancas que te explicamos a continuación cubran casi todos los escenarios de duplicado interno y externo que aparecen en una auditoría SEO.
1. Redirecciones 301 y consolidación de versiones
La forma más rápida de fundir varias URLs en una sola es un redirect 301 permanente. Con él trasladas a usuarios y bots a la versión que quieres proteger y concentras toda la autoridad en un único lugar.
- Unifica protocolos y subdominios: redirige
http --> httpsyexample.com --> www.example.com(o al revés, pero siempre hacia una única versión). - Normaliza detalles de la ruta: mayúsculas/minúsculas, barra final, extensiones
"index.html", etc. - Evita cadenas de redirecciones (301 –> 302 –> 301…) para no diluir PageRank ni ralentizar la carga.
Google confirma que los 301 son la señal de consolidación más fuerte y la manera más rápida de que los buscadores olviden la URL duplicada.
2. Uso correcto de la etiqueta rel="canonical"
Cuando varias páginas deben seguir existiendo (paginaciones, PDFs, vistas de impresión), la etiqueta canónica indica a Google cuál debe indexar.
- Colócala en el <head> con rutas absolutas.
- Autorreferencia: la canónica también deben apuntarse a sí misma.
- Una sola por documento: múltiples canonicals confunden al buscador.
<link rel="canonical" href="https://midominio.com/camiseta-basica/" />
La canónica es casi tan potente como un 301, pero útil solo cuando ambas URLs siguen activas.
3. Meta robots noindex, hreflang y manejo de parámetros
Algunas páginas han de existir (resultados de búsqueda interna, filtros muy concretos) pero fuera del índice. Añade en su cabecera:
<meta name="robots" content="noindex,follow" />
Con parámetros (?utml=, filtros) puedes o bien canonizar hacia la URL limpia o marcarlos noindex si no aportan valor de búsqueda.
En sitios multilingües, declara variaciones legítimas con hreflang para que Google no las considere duplicadas.
4. Buenas prácticas de arquitectura y taxonomía
- Diseña categorías exclusivas; evita que un mismo post aparezca en decenas de etiquetas vacías.
- Centraliza variaciones de producto: una URL, atributos dinámicos (color/talla) y, si los filtros crean páginas nuevas, canónica a la principal.
- Planifica slugs estables: que el cambio de título no genere una nueva dirección cada vez.
- Auditoría periódicas con Screaming Frog o el informe de Indexación de Search Console te avisarán de duplicados nuevos antes de que escalen.
Básicamente, redirecciona lo que ya no necesitas, canoniza lo que debe convivir, "noindexes" lo que carece de intención de búsqueda y diseña tu sitio para que cada intención de búsqueda se represente con una única URL. Así mantendrás el 90% de los problemas de contenido duplicado bajo control.
Qué hacer cuando te copian: protege tu autoría
Primero confirma que la copia existe: el truco más rápida es buscar en Google un párrafo de tu contenido entre comillas; si aparece otro dominio antes que el tuyo, anótale. Para revisiones rutinarias vale la pena apoyarse en detectores como Copyscape, que comparan tu URL con todo el índice de la web y muestran coincidencias en segundos.
Complementa ese chequeo con alertas de marca o de frase únicas en Google Alerts, Ahrefs o Semrush para enterarte al instante cuando alguien replica tu contenido.
Cuando identifiques un plagio, recopila capturas y las URLs de la copia y presenta una solicitud de retirada por copyright (DMCA). Google facilita un formulario específico, Copyright infringement – Web Search, donde indicas tus datos, la página legítima y la infractora; si todo está en regla, la versión pirateada suele desaparecer de las SERP en pocos días.
Para evitar sorpresas a futuro, programa revisiones automáticas: un rastreo mensual con Copyscape o una alerta de mención de dominio en Ahrefs te avisará cada vez que tu texto aparezca fuera de tu web. Así actúas antes de que la copia gane autoridad o capte enlaces que deberían apuntar a tu web.
En resumen, la clave es vigilar, actuar rápido y documentar cada reclamación: con ello mantendrás intacta tu reputación, tu EEAT y la visibilidad lograda con contenido original.
Y si sospechas de que el plagio externo o el duplicado interno están frenando tu crecimiento orgánico, contacta con el equipo de Potencial SEO para una auditoría completa y un plan de acción hecho a tu medida.
Preguntas frecuentes sobre el contenido duplicado
No; Google no trabaja con un umbral fijo de % de coincidencia. Lo que detecta son bloques sustanciales muy parecidos, y decide si necesita mostrar solo una versión. No publica cifras ni notas de corte.
Sí. Las plataformas sociales no indexan los posts de forma convencional (o los bloquean con noindex), así que no generan duplicado que compita con tu web.
Google trata cada idioma como contenido distinto siempre que uses hreflang o subdirectorios/subdominios separados. Una traducción automática sin localización puede verse como baja calidad, pero no como duplicado.
No. Google entiende que esas secciones se repiten en todas las páginas y las filtra antes de comparar el cuerpo principal. Lo problemático es que la parte única sea demasiado pequeña frente al boilerplate.
La 301 es la señal más contundente porque elimina la URL antigua e informa a Google de que el contenido se ha movido de forma permanente. La canónica es casi tan potente, pero se usa cuando ambas URLs deben coexistir.
No hay penalización automática; Google filtra o consolida las versiones duplicadas. Solo las copias con intención manipuladora (spam) pueden recibir una acción manual.







